Xpath
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、
介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言。
Xpath简单语法
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
bookstore 选取 bookstore 元素的所有子节点。
/bookstore 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。
//book 选取所有 book 子元素,而不管它们在文档中的位置。
bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。
//@lang 选取名为 lang 的所有属性。
Xpath 也是支持逻辑运算符的
实例
爬取豆瓣Top250电影排行
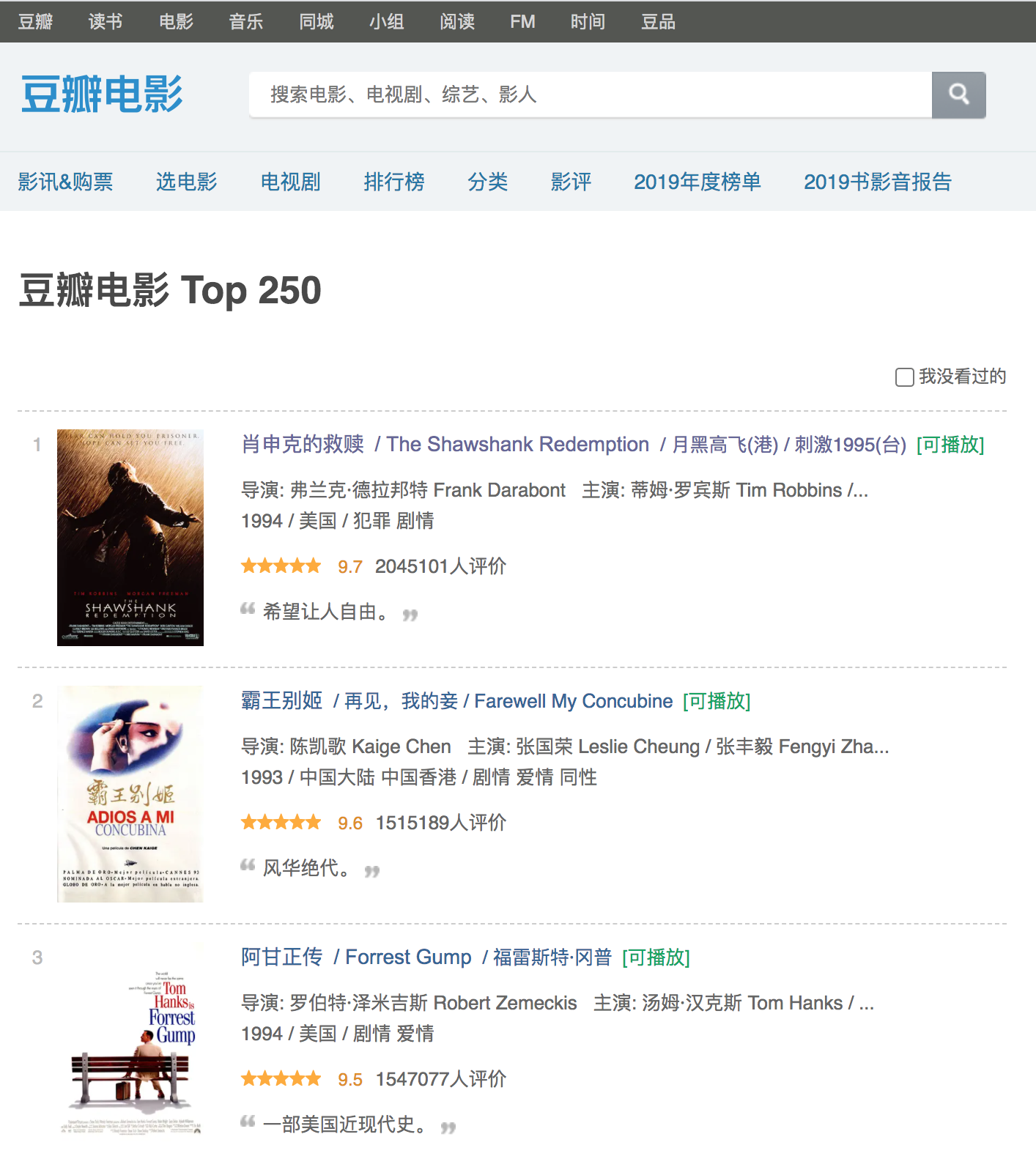
原理
由于豆瓣是有反爬机制的我们需要伪装一下自己的请求,也就是 User-Agent 对于User-Agent F12开发者工具中请求能找到主要是通过伪装浏览器去访问目标链接,
我这里的请求用到的是 requests 模块没有使用urllib,这个是豆瓣的目标链接url = 'https://movie.douban.com/top250?start=',主要是通过这个链接区爬取
数据由于每页只有25条数据,通过发现翻页是url的变化找到规律,就是 i * 25 (i从1 - 10)就能爬下250条数据,
源码
import time
import pymysql
import requests
from lxml import etree
import pandas as pd
header = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'
}
url = 'https://movie.douban.com/top250?start='
data = []
def get_data(url):
html = requests.get(url, headers=header)
selector = etree.HTML(html.content.decode('utf-8'))
text = selector.xpath('//*[@id="content"]/div/div[1]/ol/li')
for item in text:
pic = item.xpath('div/div[1]/a/img/@src')[0]
zh_title = item.xpath('div/div[2]/div/a/span[1]/text()')[0]
or_title = item.xpath('div/div[2]/div/a/span[2]/text()')[0]
if or_title:
or_name = or_title.replace("/", "").replace(" ", "").replace("\xa0", "").replace(r"\xa0/\xa0", "")
else:
or_name = ''
direct = item.xpath('div/div[2]/div[2]/p[1]/text()')[0]
dire = str(direct).replace("\n", "").replace(" ", "").replace("\xa0", "")
rating_num = item.xpath('div/div[2]/div[2]/div/span[2]/text()')[0]
pj = item.xpath('div/div[2]/div[2]/div/span[4]/text()')[0]
theme = item.xpath('div/div[2]/div[2]/p[2]/span/text()')
# data.append({'海报': pic,
# '电影名': zh_title,
# '英文名': or_name,
# '导演主演信息': dire,
# # '主演': dire[3],
# '评分': rating_num,
# '评价人数': pj,
# '主题': theme[0] if theme else ''})
data.append({'pic': pic,
'title': zh_title,
'or_title': or_name,
'dire': dire,
# '主演': dire[3],
'rating_num': rating_num,
'pj': pj,
'theme': theme[0] if theme else ''})
print(data)
return data
def commit_db(table,datas):
keys = datas[0].keys()
print(keys)
columns = ','.join(keys) # 'name,age,height,mobile'
print(columns)
values = ')s,%('.join(keys) # 'name)s,%(age)s,%(height)s,%(mobile'
print(values)
sql = """INSERT INTO %s (%s) VALUES (%%(%s)s)""" % (table, columns, values)
print(sql)
conn = pymysql.connect(database='douban_movie', user='root', password='19981008', host='127.0.0.1',
port=3306)
cur = conn.cursor()
# cur.executemany(sql, datas)
conn.commit()
cur.close()
conn.close()
if __name__ == '__main__':
for i in range(1):
url = 'https://movie.douban.com/top250?start={}&filter='.format(i * 25)
get_data(url)
print('第{}页已经爬取完'.format(i + 1))
time.sleep(1)
movie_info = pd.DataFrame(data)
movie_info.to_excel('豆瓣Top250.xlsx')
commit_db('movie', data)
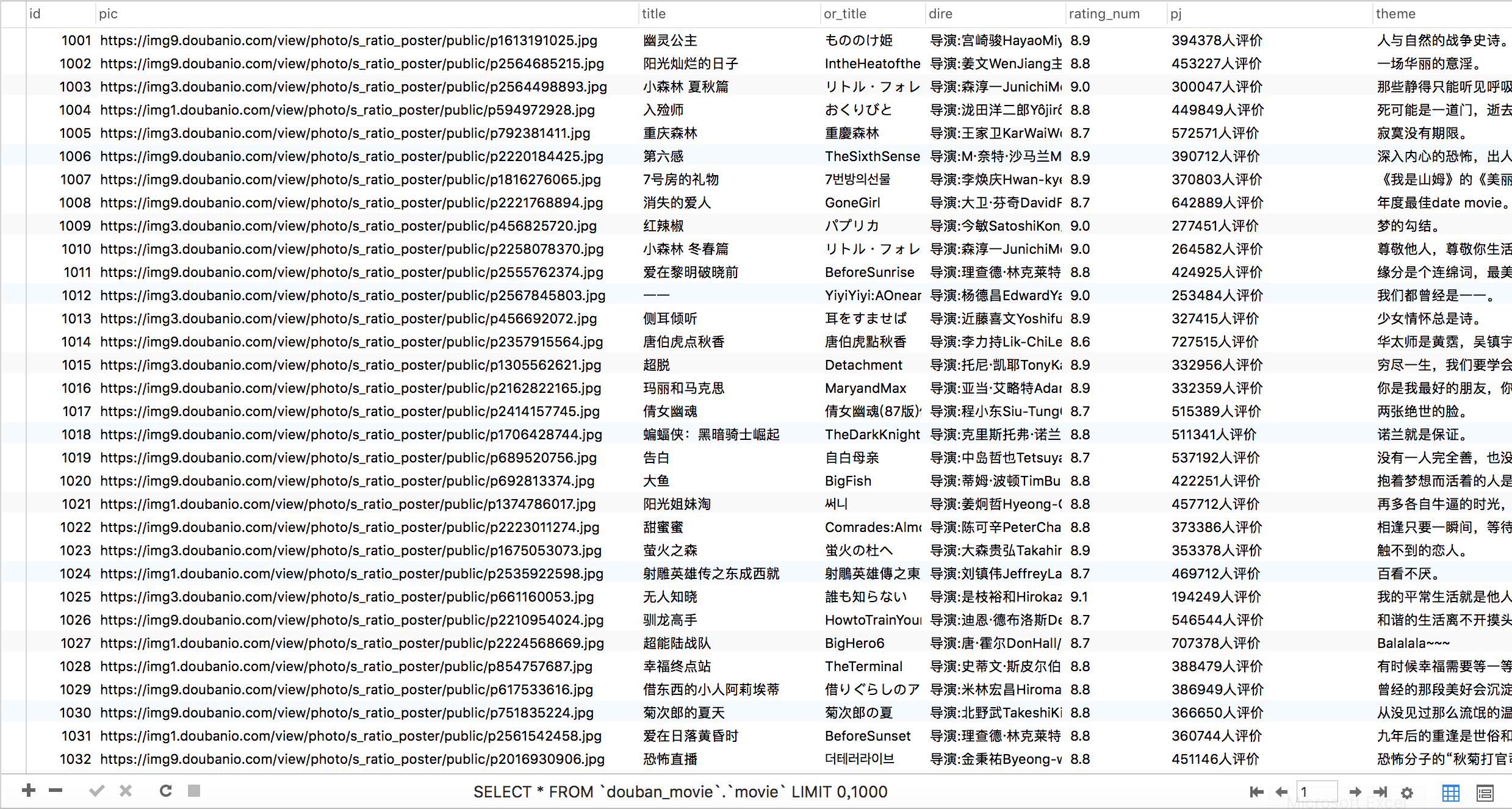
效果图
Excel效果图

Mysql效果图
总结
爬虫最重要的还是要思路清晰,在HTML文本中找到对应你想爬取的内容,并用类似bs , Xpath这样的工具去解析, 其次遇到翻页也要去找翻页url的规律就像这个实例一样,在Chrome中Xpath有个好用的插件 Xpath Helper,可以通 过插件找到内容后,粘贴到代码还是挺方便的,这个实例中处理反爬仅仅用到了User-Agent,其实反爬机制还是有很多 东西可以探索的,后续博客会有更新到内容,这个实例可以当做大家的入门实例,希望大家好好学习,也可以给博主提提 意见